本チュートリアルは、 データベース・デジタルライブラリーChinese Text Project(中国哲学書電子化計画)における一般的なタスク機能について、ユーザーの目線からまとめたものです。皆さんに参考となりそうなシステムの主要機能に関するタスク事例をご紹介します。
本チュートリアルのオンライン版はこちら:
英語:https://dsturgeon.net/ctext
中国語:https://dsturgeon.net/ctext-zh
日本語:https://dsturgeon.net/ctext-ja
初期設定
- アカウントの登録:左側のペインを一番下までスクロールダウンしてください。「Log in」をクリックし、「If you do not have an account…」セクションにおいて必要事項を記入してください。
- フォントサポートを確認:左上の隅に見える「About the site」の下にある「Font test page」をクリックしてください。
テキストを探す
- 左側のペインにある「Title search」機能をお使いください。
- 題目検索結果において、「
 」アイコンが表示されているテキストは、スキャンした資料とリンクしています。
」アイコンが表示されているテキストは、スキャンした資料とリンクしています。
- 題目検索結果において使用される主なアイコン:
 テキストデータベースにおける複写版(ユーザーは編集不可)
テキストデータベースにおける複写版(ユーザーは編集不可)
 ユーザーが編集可能な複写版、OCRは使用されていません
ユーザーが編集可能な複写版、OCRは使用されていません
 ユーザーが編集可能な複写版、OCRに対応しています
ユーザーが編集可能な複写版、OCRに対応しています
 特定の編集されたテキストのスキャン版
特定の編集されたテキストのスキャン版
- 実践:
- 『資暇集』の複写版を検索してください
- テキストデータベースにて、先秦もしくは漢のテキストを検索してください。
全文検索
- まず、検索したいテキスト(もしくは章や巻)を検索し、開いてください。その後、左側のペイン下部にある「Search」というボックスを使用してください。
- 実践:
- 『論語』にて、孔子が「君子不器」と述べている節を検索してください。
- 『莊子』の中で、「道」について書かれている節すべてを検索してください。
- テキストデータベースにて、テキストを検索している際、数多くの検索結果が出る事があります。その場合、右上に表示されている「Show statistics」というリンクを使用することで検索結果がどこで表れているのか、インタラクティブな概要を見ることができます。
主要なスキャン資料の中でテキストを特定する
- ctextにおいて、スキャンしたテキストは、linked transcriptionsといった方法で検索することができます。仮に、複写版にリンクしたテキストがある場合、題目検索結果にて「」アイコンが表示されます。
- スキャン版にリンクしているテキストの場合、如何なるテキスト段落の左側に表示されている「」アイコンをクリックすることで、該当のスキャン版テキストを開くことができます。
- スキャンされたテキストにおいて、特定の単語や語句を検索するには、対応する複写版にてその単語や語句を検索し、検索結果左側に表示されている「」アイコンをクリックしてください。
- 特にOCRを使用して作成されている複写版において、複写のエラーは、長い語句であるほど、マッチしないという事を表していることがあります。その際、単語より短い語句を検索するか、検索しているテキストの近くに表示されている単語を使用してください。
- 実践:
- スキャンのリンクがあるテキストを探し、スキャン版の中で検索し、結果を考察してください。
- OCRのある複写版で試してください。
- テキストは、スキャンしたテキストを所蔵しているウェブサイトの「Library」セクションからも検索できます。この作業は、リンクした複写を検索するときと全く同じ結果となります。
- もしくは、提供されたリンクを使用して、スキャン版をページごとに検索する事も出来ます。
テキストの節と類似するテキストを検索する
テキストデータベースでは、先秦及び漢テキスト、類書の検索ができます。
- テキストの一節を選んで、「
 」アイコンをクリックし、類似した部分の概要を表示することができます。
」アイコンをクリックし、類似した部分の概要を表示することができます。
- 検索結果において、表題付近にある「
 」アイコンをクリックすることで、どの文脈で出現しているのか表示されます。
」アイコンをクリックすることで、どの文脈で出現しているのか表示されます。 - 実践:
- 古典言語資料で著名な『莊子』の「庖丁解牛」と類似している箇所を検索してください。
2つの特定テキストにおいて類似した箇所を検索する
テキストデータベースでは、先秦及び漢テキスト、類書の検索ができます。
- 左側のペイン下部にある「Advanced search」リンクをクリックしてください。
- 「1. Scope」と表示されているセクションにおいて、検索したい1つ目のカテゴリー、テキストもしくはテキストユニットを選んでください。例えば、『莊子』において、「Pre-Qin and Han」、「Daoism」、「Zhuangzi」を選んでください(4つ目のボックスは、「All」としてください)。
- 「3. Search parameters」のセクションでは、「Parallel passage search」の下にあるボックスにチェックを入れてください。先程と同様の手順で、類似を検索したいカテゴリー、テキストもしくはテキストユニットを選択してください。
- 「Search」をクリックしてください。検索結果では、すべての類似した節が表示されます。
- 実践:
- 『論語』及び「Daoism」カテゴリー内のテキストの間でどのような類似があるのか、検索してください。
- 検索結果が出た後、「Show statistics」リンクをクリックしてみてください。
- 次に、同様の検索をしてください。ただし、この場合、「Scope」と「Search parameters」を逆転し、その後、「Show statistics」を使用してみてください。
コンコルダンス番号を使用して、テキストを検索する
コンコルダンス情報を含むテキストに対応できます。
- まず、複写したテキストのコンテンツを開いてください。ページの右側に、検索ボックスが表示され、テキストに対応した一致の数がそれぞれ表示されます。
- 実践:
- Eric Huttonのこの論文にて、著者はICSとハーバード燕京に使用されている一致の数をもとに、中国語のテキストを引用することなく、テキストの引用箇所を表示しています。例えば:


ctext.orgにおけるコンコルダンス検索機能を使用することで、参考資料17にて、著者が訳し、引用した「荀子」の箇所と対応する原文の中国語を特定することができます。
- Eric Huttonのこの論文にて、著者はICSとハーバード燕京に使用されている一致の数をもとに、中国語のテキストを引用することなく、テキストの引用箇所を表示しています。例えば:


テキストにおいてコンコルダンス番号を検索するには
コンコルダンス情報を含むテキストに対応できます。
- コンコルダンスに対応している節において、左側に表示されている「
 」アイコンをクリックしてください。
」アイコンをクリックしてください。 - マウスを表示された節内で動かすことによって、そのテキストの一部においてコンコルダンス列全てが表示されます。
- 一定の節に関係するコンコルダンス列のみを表示させるのは、マウスをハイライトされているテキスト(緑色)まで動かしクリックしてください。ハイライトされたテキストを含むすべてのコンコルダンス列が表示されます。
- 実践:
- 前述の例に従って、「荀子」における「人之性惡,其善者偽也」と対応するコンコルダンス列を特定してください。
テキストと翻訳を並べて検証する
英語の翻訳があるテキストに対応しています
- 通常、テキストの翻訳を見る際、1つの中国語の段落が表示され(恐らくかなり長い)、次に対応した英語の段落が表示されます。テキストと翻訳をより近くに表示することも可能です(一般的には、語句ごとに)。この作業をするためには、テキスト節の左側にある「」アイコンをクリックしてください。この機能は、マウスのカーソルが中国語のテキストに移動した際、辞書情報を表示することもできます。
- 長い節では、特定の中国語テキストに対応する翻訳の箇所に直接移動することをお勧めします。その作業を行うには、中国語語句のテキストを検索し、前述通り、「」アイコンをクリックしてください。
- 実践:
- 『莊子』のテキストで実験をしてください。
- James Leggeが如何に「每至於族,吾見其難為,怵然為戒,視為止,行為遲」を翻訳しているのか調べてください。
注釈を見る
『論語』、『孟子』、『墨子』、『道德經』などといった特定のテキストに対応します。
- テキスト節の左側にある「
 」アイコンをクリックしてください。注釈は、独立したテキストですので、表示された注釈のリンクを使用することで、注釈のないテキストの代わりに、注釈のあるテキストを読むことができます。
」アイコンをクリックしてください。注釈は、独立したテキストですので、表示された注釈のリンクを使用することで、注釈のないテキストの代わりに、注釈のあるテキストを読むことができます。 - 実践:
- 『論語』、『孟子』、『墨子』、もしくは『道德經』で実験してみてください。
稀な、異形の文字を検索、入力する
- ウェブサイトにおいて、「Dictionary」セクションを開いてください。
- 文字によっては、以下の作業が必要となるでしょう:
- 直接入力(文字をタイプしてください)
- 構成要素の検索:辞書のメイン画面における概要を参照してください
- 語根の検索:まず語根を選び、付加の画数を使用してください。「n strokes」ラベルをクリックすることで、表示される文字のサイズを大きくすることができます。
- 実践:
- 䊫、𥼺、𧤴… 、これらの文字をctext.orgで検索してください(このページからコピーやペーストをしないでください!)
- ヒント:構成要素のいずれかを容易に入力する事が出来ない場合、代わりにその構成要素を含むどの文字でも結構ですので入力してください。このように分解することで構成要素を特定できます。次に、その構成要素を含む他の文字を検索してください。
- ユニコードに存在しない異形の文字へのサポートはctext.orgに書き加えられています。これらは、構成要素を通じてのみ検索することができます。
- ユニコードに掲載されていない文字は、ctextで使用する際に、コピーペーストすることができます。ユニコードで掲載されていない文字がコピーされた場合、「ctext:nnnn」認識子となります(例えば、ctext:1591)。これを他のソフトウェア(Microsoft Wordなど)にペーストした場合、文字やイメージではなく、この認識子が貼り付けられます。
- ただし、ctextにて文字を右クリックし、「Copy image」を選択することで、文字のイメージをワード書類にコピーすることができます。その際、ctext.orgからイメージを取得しているという事を引用してください(例えば、「ctext:nnnn」認識子を引用するか、そのURLを提供してください)。
- 例えば:

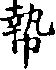


複写版を編集する
最も簡単な方法で、スキャン版にリンクしているテキストを正す為には、「Quick edit」機能を使用してください。以下の作業をしてください:
- 複写エラーが出ているスキャンしたページを特定してください。
- 「Quick edit」リンクをクリックしてください。
- 編集可能なページの複写が表示されます。通常、複写の各列は、スキャンしたテキストの列に該当しています。
- スキャン版を照らし合わせ、慎重に複写版を修正してください。「Save changes」をクリックして終了してください。
- スペースが必要な場合、英語で使用する半角スペースではなく、中国語で使用する全角を入力してください。
- 実践:
- OCRによって自動的に作成された複写版を選び、エラーを修正してください。
- 「バージョニング(versioning)」:各テキストにおけるすべての変更を記録し、変更前の状態に戻すことが可能なオプションを維持するという機能です。この機能は、如何なるwikiシステムにおいても基本的なオペレーションです。修正を保存した後:
- 「View」リンクをクリックし、修正したテキスト複写を開いてください。
- ページの一番上までスクロールし、「History」をクリックすることで、最新の変更リストを表示してください。最も新しい編集は一番上に表示されます。
- 各列は、特定の編集が行われた複写の状況を表示しています。2つの編集を比較したい場合、図の左側にあるラジオボタンで2つの項目を選び、「Compare」をクリックしてください。デフォルトの設定では、常に最新の編集、およびその前に行われた編集を比較します。「Compare」をクリックし、あなたが先程行った編集の可視化を行ってください。
プラグインのインストールと使用方法
プラグインは、ウェブサイトのユーザーインターフェイスをカスタマイズ化し、付加機能をサポートすることができます。一般的に、テキストデーターのダウンロード、第三の文字字典への接続が事例として挙げられます。プラグインを使用するには、必ずあなたのアカウントにそのプラグインをインストールしておく必要があります(1つのプラグインにつき、1回のみの作業です)。プラグインをインストールするには:
- 「About the site」をクリックし、その後、「Tools」、「Plugins」を開いてください。
- 追加したいプラグインを特定し、「Install」をクリックしてください。
- その後表示される確定画面にて、「Install」をクリックしてください。
一旦インストールが完了すると、ctext.orgにてサポートされているオブジェクトのいずれかを開いた場合(例えば、「book」もしくは「chapter」プラグインにおけるテキストの章、「character」や「word」類のプラグインにおける辞書内の文字)、スクリーン上部付近のバーにて、該当するリンクが表示されます。
実践:
- 「Plain text」プラグインをインストールし、それを使ってテキストの章をエクスポートしてください。
- 「Frequencies」プラグインをインストールし、それを使ってテキストの章における文字の頻度を見てください。
- 「character」や「word」類におけるプラグインのいずれかをインストールしてください。それを使って、辞書の中で文字を探したり、外部辞書にアクセスしたりしてください。
上級トピック
以下では、より上級なトピックを紹介します。これらは、本チュートリアルの範囲を超えており、皆さんの更なる試み、(もしくは)高度な技術的スキルが必要とされます。
新しいプラグインを作成する
プラグインは、ctext.orgのユーザーインターフェイスを外部のリソース(多くはその他ウェブサイト)と接続する為のXML形式のプログラミング言語です。新しいプラグインは、ctext.orgのアカウントにおいて、既存のプラグインのコードを修正することで、直接作成することができます。どのようなプラグインがインストールされているのか確認するには、左側のペインにある「Settings」をクリックし、「editing your XML plugin file」リンクをクリックしてください。
新しいプラグインを作成するには、<Plugin>…</Plugin>タグの間にコードを重複し、その重複を編集することが必要です。その際、<Update>タグを新しいプラグインから除外する必要があります。そうしなければ、将来上書きされる可能性があります。もしくは、XMLファイルのスタンドアローンを作成し(多くの既存事例を参照してください)、それをあなたのサーバーにホストし、ctext.orgのアカウントにインストールしてください。
仮に、新しいプラグインに何らかの問題があったり、コードがctextインターフェイスに受けいれられなかった場合、W3C Markup Validatorを使用して、プラグインファイルが有効であるかどうか確認することができます。有効なプラグインファイルは、緑色で「This document was successfully checked as CTPPlugin!」と、このように表示されます。
プログラミングによるアクセス
ウェブサイトのテキスト資料は、プログラミング言語のパイソン(Python)などから直接アクセスすることができます。特にプログラミングの経験がない方にとって、この作業には、より多くのセットアップに加え時間が必要とされますが、これについての作業説明もオンラインで取得可能です。
プログラミングのアクセスは、ctext.org のApplication Programming Interface (API)によって促進されており、如何なる言語、もしくはHTTPリクエストを送信できる環境でしたら、作業可能です。この作業には、特段パイソンをお勧めします。といいますのも、ctext Python moduleが存在することで、少ない労力でAPIにアクセスできるからです。APIの一般的な付随資料に加え、全てのAPI機能に関する付随資料が入手可能で、各種実例が含まれています。





