This tutorial briefly summarizes some of the most common tasks on the Chinese Text Project database and digital library from a user perspective, with suggested example tasks intended to introduce core functionality of the system.
Online versions of this tutorial:
English: https://dsturgeon.net/ctext
Chinese: https://dsturgeon.net/ctext-zh
Japanese: https://dsturgeon.net/ctext-ja
Initial setup
- Create an account: Scroll down to the bottom of the left-hand pane and click “Log in”, then fill out the “If you do not have an account…” section.
- Check font support: Under “About the site” near the top-left corner, click on “Font test page”.
Finding texts
- Use the “Title search” function on the left-hand pane.
- Texts that display the “
 ” icon in title search results are linked to scanned sources.
” icon in title search results are linked to scanned sources. - Key to icons used in title search results:
 Transcription in the textual database (not user editable).
Transcription in the textual database (not user editable).
 User-editable transcription, not generated using OCR.
User-editable transcription, not generated using OCR.
 User-editable transcription generated using OCR.
User-editable transcription generated using OCR.
 Scanned copy of a particular edition of a text.
Scanned copy of a particular edition of a text.
- Exercise:
- Locate a transcription of the 資暇集.
- Locate a pre-Qin or Han dynasty text in the textual database.
Full-text search
- First locate and open the transcription of the text (or chapter/juan) you wish to search in, then use the box labeled “Search” near the bottom of the left-hand pane.
- Exercise:
- Locate the passage in the Analects where Confucius says “君子不器”.
- Locate all passages in the Zhuangzi where “道” is mentioned.
- When you search a text in the textual database and get many results, you can use the “Show statistics” link at the top-right to display an interactive summary of where the results appear.
Locating text in scanned primary sources
- On ctext, scanned representations of texts are searched by means of linked transcriptions. If a transcription has a linked text, it will be display the “” icon in the title search results.
- Where a text is linked to a scan, clicking the “” icon to the left of any paragraph of text opens the corresponding page of the scan.
- To search for a specific term or phrase in a scanned text, search the associated transcription for the term or phrase, then click the “” icon to the left of the search result.
- Particularly in cases where transcriptions have been created using OCR, errors in the transcription may mean that longer phrases are not matched. Try searching for a shorter phrase, or using words that should appear nearby the text you are looking for.
- Exercise:
- Locate a text with scan links, and try searching and viewing the results within the scanned representation.
- Try doing this with an OCR-derived transcription
- Texts can also be searched from the “Library” section of the site containing the scanned texts – this produces exactly the same result as searching the linked transcription.
- You can also navigate through the scanned representation page by page using the links provided.
Finding parallels to a passage of text
Available for pre-Qin and Han texts and Leishu in the textual database.
- Locate a passage of text, then click the “
 ” icon to display the parallel summary.
” icon to display the parallel summary. - Within the results, click the “
 ” icon beside a heading to display each result along with the context in which it occurs.
” icon beside a heading to display each result along with the context in which it occurs. - Exercise:
- Find what parallels there are in the classical corpus to the famous passage in the Zhuangzi describing Pao-ding 庖丁 cutting up an ox.
Finding parallels between two particular texts
Available for pre-Qin and Han texts and Leishu in the textual database.
- Click the “Advanced search” link towards the bottom of the left-hand pane.
- In the section labeled “1. Scope”, select the first category, text, or textual unit you wish to search in. For example, to search within the Zhuangzi, you would choose “Pre-Qin and Han”, “Daoism”, then “Zhuangzi” (and leave the fourth box with “[All]” in it).
- In the section labeled “3. Search parameters”, tick the box under “Parallel passage search”, and select in the category, text, or textual unit you wish to locate parallels to in the same way as the previous step.
- Click “Search”. The results will list all passages containing parallels.
- Exercise:
- Try locating all parallels between the Analects and texts in the “Daoism” category.
- When you have the results, try clicking the “Show statistics” link.
- Perform the same search again, but with the “Scope” and “Search parameters” reversed, and again try using “Show statistics”.
Locating text by concordance number
Available for texts with concordance data.
- First open the contents page for the transcription of the text. On the right hand side of the page, one search box will be displayed for each type of concordance number supported for that text.
- Exercise:
- In this paper by Eric Hutton, the author uses concordance numbers from both the ICS series and the Harvard Yenching series to identify textual references without quoting the Chinese text, e.g. here:


Use the concordance lookup function on ctext.org to locate the original Chinese corresponding to the passage the author translates and references in footnote 17 above in Xunzi.
- In this paper by Eric Hutton, the author uses concordance numbers from both the ICS series and the Harvard Yenching series to identify textual references without quoting the Chinese text, e.g. here:


Getting the concordance number for a piece of text
Available for texts with concordance data.
- Click the “
 ” icon to the left of any passage with concordance data available.
” icon to the left of any passage with concordance data available. - Moving the mouse over the displayed passage will cause all concordance lines to which that segment of text belongs to be displayed.
- To display only those concordance lines relevant to a particular part of the passage, click and drag with the mouse to highlight part of the text (which will appear in green). All concordance lines containing any of the highlighted section of text will be listed.
- Exercise:
- Following on from the previous example, identify the concordance lines which correspond to the line “人之性惡,其善者偽也。” in the Xunzi.
Viewing text and translation side by side
Available for texts with an English translation.
- Normally when viewing texts with translations, one (potentially quite long) paragraph of Chinese is displayed, followed by the corresponding paragraph of English. It is also possible to display the text and translation aligned much more closely (usually phrase by phrase). To do this, click the “” icon to the left of a passage of text. This function also displays available dictionary information when the mouse cursor is moved over the Chinese text.
- For long passages, it may be useful to jump straight to the part of the translation corresponding to a particular part of the Chinese text. To do this, search the text for a Chinese phrase, then click the “” icon as before.
- Exercise:
- Experiment with the text of the Zhuangzi.
- Use this to quickly see how James Legge translated the line “每至於族,吾見其難為,怵然為戒,視為止,行為遲” in that same text.
Viewing commentary
Available for selected texts including the Analects, Mengzi, Mozi, Dao De Jing
- Click the “
 ” icon to the left of a passage of text. Note that commentaries are also independent texts, so you can use the links in the displayed commentary to switch to reading the commentary instead of the uncommented text.
” icon to the left of a passage of text. Note that commentaries are also independent texts, so you can use the links in the displayed commentary to switch to reading the commentary instead of the uncommented text. - Exercise:
- Experiment with the Analects, Mengzi, Mozi, or Dao De Jing.
Locating/inputting obscure and variant characters
- Open the “Dictionary” section of the site.
- Depending on the character, you may want to use:
- Direct input, i.e. just type the character in
- Component lookup – refer to the brief instructions on the main dictionary page.
- Radical lookup – first select the radical, then look at the additional stroke count. You can increase the size of the displayed characters by clicking on the “n strokes” label.
- Exercise:
- 䊫, 𥼺, 𧤴, … – try locating these on ctext.org (without copying and pasting from this page!)
- Hint: Where you do not have an easy method of inputting either component, you can instead input any other character containing that component, use its decomposition to locate the component, and then search for other characters which also contain that component.
- Support for variant characters which do not exist in Unicode is being added to ctext.org. These can currently be looked up by components only.
- Non-Unicode characters can be copied and pasted for use within ctext. When a non-Unicode character is copied, it becomes a “ctext:nnnn” identifier (e.g. ctext:1591). Pasting this into other software (e.g. Microsoft Word) will paste this identifier, not a character or image.
- You can, however, copy the image of the character from ctext by right-clicking on the character and choosing “Copy image”, and paste this into a Word document. Please remember to cite ctext.org as the source of the image (e.g. by referencing the “ctext:nnnn” identifier, or providing its URL).
- Examples:

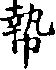


Editing a transcription
The easiest way to correct transcriptions for texts which are linked to scans is to use the “Quick edit” function. To do this:
- Locate the page of the scan on which the transcription error occurs.
- Click the “Quick edit” link.
- An editable transcription of the content of that page will appear. In general, each line of the transcription should correspond to one column of the scanned text.
- Carefully modify the transcription to agree with the scan, and click “Save changes” when done.
- If spaces are necessary, be sure to use full-width Chinese spaces and not half-width English spaces.
- Exercise:
- Choose a transcription which has been created automatically with OCR, and make a correction to it.
- “Versioning” – recording every change made to each text, and maintaining the option to revert to a previous state – is fundamental to the operation of any wiki system. After you have saved your edit:
- Open the textual transcription that you edited by clicking the “View” link.
- Scroll up to the top of that page and click “History” to display the list of recent revisions; your recent edit should be listed at the top.
- Each row represents the state of the transcription after a particular edit was made. Two edits can be compared by selecting the two using the two sets of radio buttons at the left of the table and clicking “Compare”; the default selections always compare the most recent edit with the state of the text prior to that edit. Click “Compare” to a visualization of the edit you just made.
Install and use a plugin
Plugins allow customization of the site’s user interface to support additional functionality. Common use cases include downloading textual data, and connecting to third-party character dictionaries. In order to use a plugin, you must first install it into your account (you only need to do this once for each plugin). To install a plugin:
- Open “About the site” > “Tools” > “Plugins”.
- Locate the plugin you wish to add and click “Install”.
- Click “Install” on the confirmation page which appears.
Once installed, when you open any supported object on ctext.org (e.g. a chapter of text for a “book” or “chapter” plugin, or a character in the dictionary for a “character” or “word” type plugin), a corresponding link will be displayed in a bar near the top of the screen.
Exercise:
- Install the “Plain text” plugin and use it to export a chapter of a text.
- Install the “Frequencies” plugin and use it to view character frequencies in a chapter of a text.
- Install any plugin with the “character” or “word” type, look up a character in the dictionary, and use the plugin to access the external dictionary.
Advanced topics
The following introduce more advanced topics, which require additional effort and/or additional technical skills beyond the scope of this tutorial.
Creating a new plugin
Plugins are programmatic descriptions in XML of a method of connecting the ctext.org user interface to an external resource (typically another website). New plugins can be created directly from within your ctext.org account by modifying the code for an existing plugin. To see what your installed plugins look like, click on “Settings” in the left hand pane, then click the “editing your XML plugin file” link.
You can create a new plugin by duplicating the code between the “<Plugin>…</Plugin>” tags and editing the duplicate. You should remove the “<Update>” tag from your new plugin, as this may otherwise cause it to be overwritten in future. You can also create a standalone XML file (refer to the many existing examples), host it on your own server, and then install it into your ctext.org account.
If you encounter issues with your new plugin or the code is not accepted by the ctext interface, you can use the W3C Markup Validator to confirm that your plugin file is valid. A valid plugin file should give a green “This document was successfully checked as CTPPlugin!” result which looks like this.
Programmatic access
Textual material from the site can also be accessed directly from a programming language such as Python to use for text mining and digital humanities purposes. This requires some additional setup and investment of time to achieve, particularly if you have not programmed before, but step-by-step instructions are available online.
Programmatic access is facilitated by the ctext.org Application Programming Interface (API), and can be achieved from any language or environment capable of sending HTTP requests. Python is particularly recommended, because a ctext Python module exists which can be used to access the API with very little work. In addition to the general documentation for the API, documentation for all API functions is available and includes working live examples of each.
